|
|
2002年6月 JEITAニューヨーク駐在・・・荒田 良平
「米国におけるバイオ・インフォマティックスの動向」 |
|
はじめに 今回は、米国におけるバイオ・インフォマティックスの動向について取り上げる。 近年、「バイオ・インフォマティックス」が大きく脚光を浴びている。ヒトゲノムの解読においてITが決定的な役割を果たしたことがその背景にあるのは言うまでもない。折からのIT不況もあって、「ITの次はBT(バイオ・テクノロジー)」といった声も聞かれる中、ITとBTとが重なる領域(の一部)であるバイオ・インフォマティックスに熱い視線が注がれるのは無理からぬところであろう。 本稿では、こうした中で、ITベンダー側から見たバイオ・インフォマティックスの現状と主要各社の取組みに焦点をあててみることとしたい。なお、本稿の執筆にあたってはワシントン・コア社の協力を得ている。 1.
バイオ・インフォマティックスの現状 (1)
バイオ・インフォマティックスとは 本題に入る前に、まずバイオ・インフォマティックスという言葉について触れておかなければならないだろう。 近年、様々な新聞、雑誌、ウェブサイト等で「バイオ・インフォマティックス」という言葉が使われているのを目にするが、どうもその定義はまちまちで、「コンピュータを活用して遺伝子情報を解析する技術」といった狭い意味から「ライフサイエンスとITが融合する研究領域」といった広い意味まで様々な意味で使われているようである。 ちなみに、Bioinformatics.Org(http://bioinformatics.org/)という団体のウェブサイトを見ると、以下のようになっている。 ○ 狭義のバイオ・インフォマティックス: ・ “古典的な”バイオ・インフォマティックスとは、生体分子(遺伝子を構成する核酸や遺伝子による生成物であるたんぱく質を含む)の組成や構造をコンピュータを用いて蓄積・検索・分析・予測すること。(コンピュータの進歩により“シミュレートすること”も含まれる。) ・ ポスト・ゲノム時代の“新しい”バイオ・インフォマティックス: * 生物種による遺伝子の類似点・相違点を調べることによって生物の進化を研究する比較ゲノミクス * 発育段階や病状、組織の相違等によって異なる遺伝子情報の複製数(遺伝子の発現レベル)の相対的相違を計測するDNAマイクロアレイ * 遺伝子の機能を直接的・大規模に解明する機能ゲノミクス * 遺伝子生成物(たんぱく質)同士の比較からその構造や機能を解明するプロテオミクス * たんぱく質の立体構造を解明・予測する構造ゲノミクス * 特定の分子や患者に関するあらゆる医学的実験データを管理する研究/医学インフォマティックス ○ 広義のバイオ・インフォマティックス: * 医学的画像化・画像分析 * 生物学的知見に基づく情報処理(遺伝的アルゴリズム、人工知能、ニューラル・ネットワーク) * 生物学的に得られた大量の情報の処理を行うもの すなわち、もともと生物学の中でも「分子生物学」において早くからコンピュータの高度利用が進められてきており、「バイオ・インフォマティックス=コンピュータを利用した分子生物学」であったが、ヒトゲノム計画の成功を機に、その過程で確立した配列分析手法などの情報技術の応用が期待される新たな分野が「分子生物学」領域の内外に広がってきたということである。さらに、ヒトゲノム解読によってゲノム創薬やテーラーメイド医療などの可能性が膨らみ、バイオ・医療分野全体がITにとって非常に有望な成長市場として再認識されるようになったことから、バイオ・インフォマティックスを非常に広く捉える見方まで出てきたということであろう。 もちろん、「ニューラル・ネットワークまでバイオ・インフォマティックスに含めるのは如何なものか」という声もあるであろう。例えば調査会社IDCは、ライフサイエンス分野で活用される情報技術(つまり広義のバイオ・インフォマティックス)を「バイオIT」と呼んでいる。 本稿では、「バイオ・インフォマティックス」を概ね狭義(ただし上述の“新しい”バイオ・インフォマティックスを含む)の意で用いることとしたい。 図表1 バイオIT市場に関連するライフサイエンス分野 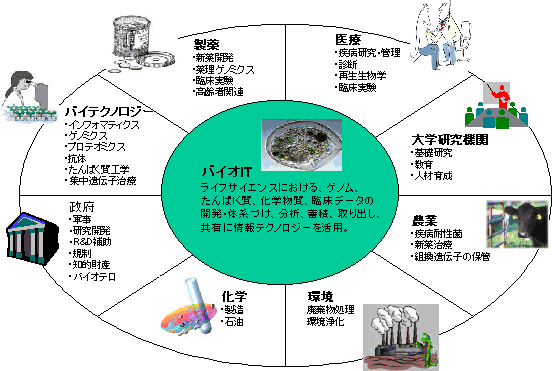 (出展: IDCの資料をもとにワシントン・コア作成)
(出展: IDCの資料をもとにワシントン・コア作成)
(2)
バイオ・インフォマティックスの発展の経緯 バイオ・インフォマティックスが大きく注目される契機となったヒトゲノム解読の顛末は、あまりにも有名な話ではあるが、念のため以下にごく簡単に触れておく。 人間の全遺伝子情報(ヒトゲノム)を国際共同研究によって解読することを目指した国際ヒトゲノム計画は、1990年に正式にスタートし、2005年の完了を予定していた。しかし、当初米国衛生研究所(NIH)でこのプロジェクトに参画していたクレイグ・ベンター氏を迎え1998年に設立されたセレーラ・ジェノミクス社が、1999年9月に実際の解読作業を始めてから1年も経たない2000年4月に、ヒトゲノムの読み取りをほぼ終了したことを明らかにした。結局、2000年6月26日にクリントン大統領、国際プロジェクトを代表するフランシス・コリンズNIH所長、及びセレーラ社のベンター社長が共同で、ヒトゲノムの解読完了を宣言したのは記憶に新しい。 セレーラ社の解読結果については、精度が低いといった批判もある。しかし、いちベンチャー企業であるセレーラ社が国際プロジェクトを出し抜かんばかりの成果を挙げたことは、世界中に衝撃を与えた。 セレーラ社は、10億ドルとも言われる資金を調達し、パーキンエルマー社(現半導体関係者にとっては懐かしい名前ですね)製の300台の最新型DNAシーケンサを並べ、コンパック(旧DEC)社製の700CPUを接続したスーパーコンピュータと70TBのストレージを導入し、「全ゲノム・ショットガン法」という力任せの解読方法の採用を可能とするアルゴリズムを開発して、これを実現した。 このセレーラ社の成功によって、バイオ・インフォマティックスの重要性とその将来性が広く認識されることとなったわけである。
|
コラムに関するご意見・ご感想は Ryohei_Arata@jetro.go.jp までお寄せください。
J.I.F.に掲載のテキスト、グラフィック、写真の無断転用を禁じます。すべての著作権はJ.I.F..に帰属します。
Copyright 1998 J.I.F. All Rights Reserved.